Instrument technicians should not have to concern themselves over the programming details internal to digital PID controllers. Ideally, a digital PID controller should simply perform the task of executing PID control with all the necessary features (setpoint tracking, output limiting, etc.) without the end-user having to know anything about those details. However, in my years of experience I have seen enough examples of poor PID implementation to warrant an explanatory section in this book, both so instrumentation professionals may recognize poor PID implementation when they see it, and also so those with the responsibility of designing PID algorithms may avoid some common mistakes.
29.15.1 Introduction to pseudocode
In order to show digital algorithms, I will use a form of notation called pseudocode: a text-based language instructing a digital computing device to implement step-by-step procedures. “Pseudocode” is written to be easily read and understood by human beings, yet similar enough in syntax and structure to real computer programming languages for a human programmer to be able to easily translate to a high-level programming language such as BASIC, C++, or Java. Since pseudocode is not a formal computer language, we may use it to very efficiently describe certain algorithms (procedures) without having to abide by strict “grammatical” rules as we would if writing in a formal language such as BASIC, C++, or Java.
Program loops
Each line of text in the following listing represents a command for the digital computer to follow, one by one, in order from top to bottom. The LOOP and ENDLOOP markers represent the boundaries of a program loop, where the same set of encapsulated commands are executed over and over again in cyclic fashion:
Pseudocode listing 46
language=pseudocode LOOP PRINT ”Hello World!” // This line prints text to the screen OUTPUT audible beep on the speaker // This line beeps the speaker ENDLOOP
In this particular case, the result of this program’s execution is a continuous printing of the words “Hello World!” to the computer’s display with a single “beep” tone accompanying each printed line. The words following a double-slash (//) are called comments, and exist only to provide explanatory text for the human reader, not the computer. Admittedly, this example program would be both impractical and annoying to actually run in a computer, but it does serve to illustrate the basic concept of a program “loop” shown in pseudocode.
Assigning values
For another example of pseudocode, consider the following program. This code causes a variable (x) in the computer’s memory to alternate between two values of 0 and 2 indefinitely:
Pseudocode listing
language=pseudocode DECLARE x to be an integer variable SET x = 2 // Initializing the value of x
LOOP // This SET command alternates the value of x with each pass SET x = 2 – x ENDLOOP
The first instruction in this listing declares the type of variable x will be. In this case, x will be an integer variable, which means it may only represent whole-number quantities and their negative counterparts – no other values (e.g. fractions, decimals) are possible. If we wished to limit the scope of x even further to represent just 0 or 1 (i.e. a single bit), we would have to declare it as a Boolean variable. If we required x to be able to represent fractional values as well, we would have to declare it as a floating-point variable. Variable declarations are important in computer programming because it instructs the computer how much space in its random-access memory to allocate to each variable, which necessarily limits the range of numbers each variable may represent.
The next instruction initializes x to a value of two. Like the declaration, this instruction need only happen once at the beginning of the program’s execution, and never again so long as the program continues to run. The single SET statement located between the LOOP and ENDLOOP markers, however, repeatedly executes as fast as the computer’s processor allows, causing x to rapidly alternate between the values of two and zero.
It should be noted that the “equals” sign (=) in computer programming often has a different meaning from that commonly implied in ordinary mathematics. When used in conjunction with the SET command, an “equals” sign assigns the value of the right-hand quantity to the left-hand variable. For example, the command SET x = 2 − x tells the computer to first calculate the quantity 2 −x and then set the variable x to this new value. It definitely does not mean to imply x is actually equal in value to 2 −x, which would be a mathematical contradiction. Thus, you should interpret the SET command to mean “set equal to . . .”
Testing values (conditional statements)
If we mean to simply test for an equality between two quantities, we may use the same symbol (=) in the context of a different command, such as “IF”:
Pseudocode listing
language=pseudocode DECLARE x to be an integer variable
LOOP
// (other code manipulating the value of x goes here)
IF x = 5 THEN PRINT ”The value of the number is 5” OUTPUT audible beep on the speaker ENDIF ENDLOOP
This program repeatedly tests whether or not the variable x is equal to 5, printing a line of text and producing a “beep” on the computer’s speaker if that test evaluates as true. Here, the context of the IF command tells us the equals sign is a test for equality rather than a command to assign a new value to x. If the condition is met (x = 5) then all commands contained within the IF/ENDIF set are executed.
Some programming languages draw a more explicit distinction between the operations of equality test versus assignment by using different symbol combinations. In C and C++, for example, a single equals sign (=) represents assignment while a double set of equals signs (==) represents a test for equality. In Structured Text (ST) PLC programming, a single equals sign (=) represents a test for equality, while a colon plus equals sign (:=) represents assignment. The combination of an exclamation point and an equals sign (!=) represents “not equal to,” used as a test condition to check for inequality between two quantities.
Branching and functions
A very important feature of any programming language is the ability for the path of execution to change (i.e. the program “flow” to branch in another direction) rather than take the exact same path every time. We saw shades of this with the IF statement in our previous example program: the computer would print some text and output a beep sound if the variable x happened to be equal to 5, but would completely skip the PRINT and OUTPUT commands if x happened to be any other value.
An elegant way to modularize a program into separate pieces involves writing portions of the program as separate functions which may be “called” as needed by the main program. Let us examine how to apply this concept to the following conditional program:
Pseudocode listing
language=pseudocode DECLARE x to be an integer variable
LOOP
// (other code manipulating the value of x goes here)
IF x = 5 THEN PRINT ”The value of the number is 5” OUTPUT audible beep on the speaker ELSEIF x = 7 THEN PRINT ”The value of the number is 7” OUTPUT audible beep on the speaker ELSEIF x = 11 THEN PRINT ”The value of the number is 11” OUTPUT audible beep on the speaker ENDIF ENDLOOP
This program takes action (printing and outputting beeps) if ever the variable x equals either 5, 7, or 11, but not for any other values of x. The actions taken with each condition are quite similar: print the numerical value of x and output a single beep. In fact, one might argue this code is ugly because we have to keep repeating one of the commands verbatim: the OUTPUT command for each condition where we wish to computer to output a beep sound.
We may streamline this program by placing the PRINT and OUTPUT commands into their own separate “function” written outside the main loop, and then call that function whenever we need it. The boundaries of this function’s code are marked by the BEGIN and END labels shown near the bottom of the listing:
Pseudocode listing
language=pseudocode DECLARE n to be an integer variable DECLARE x to be an integer variable DECLARE PrintAndBeep to be a function
LOOP
// (other code manipulating the value of x goes here)
IF x = 5 OR x = 7 OR x = 11 THEN CALL PrintAndBeep(x) ENDIF ENDLOOP
BEGIN PrintAndBeep (n) PRINT ”The value of the number is” (n) ”!” OUTPUT audible beep on the speaker RETURN END PrintAndBeep
The main program loop is much shorter than before because the repetitive tasks of printing the value of x and outputting beep sounds has been moved to a separate function. In older computer languages, this was known as a subroutine, the concept being that flow through the main program (the “routine”) would branch to a separate sub-program (a “subroutine”) to do some specialized task and then return back to the main program when the sub-program was done with its task.
Note that the program execution flow never reaches the PrintAndBeep function unless x happens to equal 5, 7, or 11. If the value of x never matches any of those specific conditions, the program simply keeps looping between the LOOP and ENDLOOP markers.
Note also how the value of x gets passed on to the PrintAndBeep function, then read inside that function under another variable name, n. This was not strictly necessary for the purpose of printing the value of x, since x is the only variable in the main program. However, the use of a separate (“local”) variable within the PrintAndBeep function enables us at some later date to use that function to act on other variables within the main program while avoiding conflict. Take this program for example:
Pseudocode listing
language=pseudocode DECLARE n to be an integer variable DECLARE x to be an integer variable DECLARE y to be an integer variable DECLARE PrintAndBeep to be a function
LOOP
// (other code manipulating the value of x and y goes here)
IF x = 5 OR x = 7 OR x = 11 THEN CALL PrintAndBeep(x) ENDIF IF y = 0 OR y = 2 THEN CALL PrintAndBeep(y) ENDIF ENDLOOP
BEGIN PrintAndBeep (n) PRINT ”The value of the number is” (n) ”!” OUTPUT audible beep on the speaker RETURN END PrintAndBeep
Here, the PrintAndBeep function gets used to print certain values of x, then re-used to print certain values of y. If we had used x within the PrintAndBeep function instead of its own variable (n), the function would only be useful for printing the value of x. Being able to pass values to functions makes those functions more useful.
A final note on branching and functions: most computer languages allow a function to call itself if necessary. This concept is known as recursion in computer science.
29.15.2 Position versus velocity algorithms
The canonical “ideal” or “ISA” variety of PID equation takes the following form:
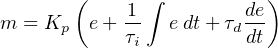
Where,
m = Controller output
e = Error (SP − PV or PV − SP, depending on controller action being direct or reverse)
Kp = Controller gain
τi = Integral (reset) time constant
τd = Derivative (rate) time constant
The same equation may be written in terms of “gains” rather than “time constants” for the integral and derivative terms. This re-writing exhibits the advantage of consistency from the perspective of PID tuning, where each tuning constant has the same (increasing) effect as its numerical value grows larger:
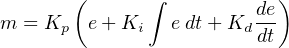
Where,
m = Controller output
e = Error
Kp = Controller gain
Ki = Integral (reset) gain (repeats per unit time)
Kd = Derivative (rate) gain
However the equation is written, there are two major ways in which it is commonly implemented in a digital computer. One way is the position algorithm, where the result of each pass through the program “loop” calculates the actual output value. If the final control element for the loop is a control valve, this value will be the position of that valve’s stem, hence the name position algorithm. The other way is the so-called velocity algorithm, where the result of each pass through the program “loop” calculates the amount the output value will change. Assuming a control valve for the final control element once again, the value calculated by this algorithm is the distance the valve stem will travel per scan of the program. In other words, the magnitude of this value describes how fast the valve stem will travel, hence the name velocity algorithm.
Mathematically, the distinction between the position and velocity algorithms is a matter of differentials: the position equation solves for the output value (m) directly while the velocity equation solves for small increments (differentials) of m, or dm.
A comparison of the position and velocity equations shows both the similarities and the differences:
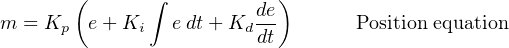
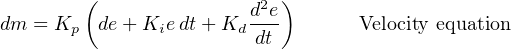
Of the two approaches to implementing PID control, the position algorithm makes the most intuitive sense and is the easiest to understand.
We will begin our exploration of both algorithms by examining their application to proportional-only control. This will be a simpler and “gentler” introduction than showing how to implement full PID control. The two respective proportional-only control equations we will consider are shown here:
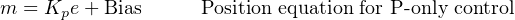
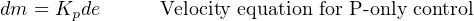
You will notice how a “bias” term is required in the position equation to keep track of the output’s “starting point” each time a new output value is calculated. No such term is required in the velocity equation, because the computer merely calculates how far the output moves from its last value rather than the output’s value from some absolute reference.
First, we will examine a simple pseudocode program for implementing the proportional-only equation in its “position” form:
Pseudocode listing for a “position algorithm” proportional-only controller
language=pseudocode DECLARE PV, SP, and Out to be floating-point variables DECLARE K˙p, Error, and Bias to be floating-point variables DECLARE Action, and Mode to be boolean variables
LOOP SET PV = analog˙input˙channel˙N // Update PV SET K˙p = operator˙input˙channel˙Gain // From operator interface
IF Action = 1 THEN SET Error = SP – PV // Calculate error assuming reverse action ELSE THEN SET Error = PV – SP // Calculate error assuming direct action ENDIF
IF Mode = 1 THEN // Automatic mode (if Mode = 1) SET Out = K˙p * Error + Bias SET SP = operator˙input˙channel˙SP // From operator interface ELSE THEN // Manual mode (if Mode = 0) SET Out = operator˙input˙channel˙Out // From operator interface SET SP = PV // Setpoint tracking SET Bias = Out // Output tracking ENDIF ENDLOOP
The first SET instructions within the loop update the PV to whatever value is being measured by the computer’s analog input channel (channel N in this case), and the K_p variable to whatever value is entered by the human operator through the use of a keypad, touch-screen interface, or networked computer. Next, a set of IF/THEN conditionals determines which way the error should be calculated: Error = SP − PV if the control action is “reverse” (Action = 1) and Error = PV − SP if the control action is “direct” (Action = 0).
The next set of conditional instructions determines what to do in automatic versus manual modes. In automatic mode (Mode = 1), the output value is calculated according to the position equation and the setpoint comes from a human operator’s input. In manual mode (Mode = 0), the output value is no longer calculated by an equation but rather is obtained from the human operator’s input, the setpoint is forced equal to the process variable, and the Bias value is continually made equal to the value of the output. Setting SP = PV provides the convenient feature of setpoint tracking, ensuring an initial error value of zero when the controller is switched back to automatic mode. Setting the Bias equal to the output provides the essential feature of output tracking, where the controller begins automatic operation at an output value precisely equal to the last manual-mode output value.
Next, we will examine a simple pseudocode program for implementing the proportional-only equation in its “velocity” form:
Pseudocode listing for a “velocity algorithm” proportional-only controller
language=pseudocode DECLARE PV, SP, and Out to be floating-point variables DECLARE K˙p, Error, and last˙Error to be floating-point variables DECLARE Action, and Mode to be boolean variables
LOOP SET PV = analog˙input˙channel˙N // Update PV SET K˙p = operator˙input˙channel˙Gain // From operator interface SET last˙Error = Error
IF Action = 1 THEN SET Error = SP – PV // Calculate error assuming reverse action ELSE THEN SET Error = PV – SP // Calculate error assuming direct action ENDIF
IF Mode = 1 THEN // Automatic mode (if Mode = 1) SET Out = Out + (K˙p * (Error – last˙Error)) SET SP = operator˙input˙channel˙SP // From operator interface ELSE THEN // Manual mode (if Mode = 0) SET Out = operator˙input˙channel˙Out // From operator interface SET SP = PV // Setpoint tracking ENDIF ENDLOOP
The code for the velocity algorithm is mostly identical to the code for the position algorithm, with just a few minor changes. The first difference we encounter in reading the code from top to bottom is that we calculate a new variable called “last_Error” immediately prior to calculating a new value for Error. The reason for doing this is to provide a way to calculate the differential change in error (de) from scan to scan of the program. The variable “last_Error” remembers the value of Error during the previous scan of the program. Thus, the expression “Error − last_Error” is equal to the amount the error has changed from last scan to the present scan.
When the time comes to calculate the output value in automatic mode, we see the SET command calculating the change in output (K_p multiplied by the change in error), then adding this change in output to the existing output value to calculate a new output value. This is how the program translates calculated output increments into an actual output value to drive a final control element. The mathematical expression “K_p * (Error − last_Error)” defines the incremental change in output value, and this increment is then added to the current output value to generate a new output value.
From a human operator’s point of view, the position algorithm and the velocity algorithm are identical with one exception: how each controller reacts to a sudden change in gain (K_p). To understand this difference, let us perform a “thought experiment” where we imagine a condition of constant error between PV and SP. Suppose the controller is operating in automatic mode, with a setpoint of 60% and a (steady) process variable value of 57%. We should not be surprised that a constant error might exist for a proportional-only controller, since we should be well aware of the phenomenon of proportional-only offset.
How will this controller react if the gain is suddenly increased in value while operating in automatic mode? If the controller executes the position algorithm, the result of a sudden gain change will be a sudden change in its output value, since output is a direct function of error and gain. However, if the controller executes the velocity algorithm, the result of a sudden gain change will be no change to the output at all, so long as the error remains constant. Only when the error begins to change will there be any noticeable difference in the controller’s behavior compared to how it acted before the gain change. This is because the velocity algorithm is a function of gain and change in error, not error directly.
Comparing the two responses, the velocity algorithm’s response to changes in gain is regarded as “better-mannered” than the position algorithm’s response to changes in gain. When tuning a controller, we would rather not have the controller’s output suddenly jump in response to simple gain changes47 , and so the velocity algorithm is generally preferred. If we allow the gain of the algorithm to be set by another process variable48 , the need for “stable” gain-change behavior becomes even more important.